

How Ticketmaster Handles Ticket Surges at 14 Million Requests per Minute
How Ticketmaster Handles Ticket Surges at 14 Million Requests per Minute
Cloud Chirp #18 ☀️ - Read Now (4 minutes)

Once every wile, there’s a Taylor Swift concert on the horizon.
And a single biggest issue people have is: buying tickets.
One inevitable fact is that there’s always more people than the number of available tickets.
And the rule is first come first served.

What makes this even more challenging is that the nature of legitimate traffic has changed.
To exploit this many choose to run “intelligent” agents (i.e., bots) to help them shop, win eBay auctions and so on — including buy tickets the users can later resell at a high markup.
So the race is more like.

Ideally, the bot traffic would be filtered out, but this is technically challenging.
And, adding to the challenge, the ticket website can only handle a limited number of purchases simultaneously.
So Ticketmaster engineers thought hard.
And came up with 8 simple ideas to handle the Ticket Surges.
1. Filtering Bot Accounts
First, they thought filtering by IP can solve their problems, but the way the modern internet works with network address translation, they ran into a lot of problems doing that.
Fingerprinting TLS connections with JA3 and JA3S hashes worked for a while, but then bot software started varying the TLS parameters so that didn’t work well anymore.
CAPCHAs also weren’t as effective as they used to be because we have AI systems that can solve them, so they had to do a better job.
Then they came up with an idea of Verified Fan system, which provides codes to confirmed users.

But once you filter most of the illegitimate, the website still needed to handle millions of legitimate users.
How can they be sure the system will handle it?
2. System Load Testing
The idea is to push the system to the point where it can no longer handle the load, so they can see what happens and then look at possible mitigations.
And a system load test provides a means for that.
They gathered all the data for this, they identified the biggest bottlenecks and address it — then repeat the test until they are able to meet the scale they need.
The reason for working this way — as opposed to fixing multiple bottlenecks between each test run — is that the next main bottleneck is often in an entirely different component of the system.
However, system resources are always limited.
So what happens when you push the thing too far?
Does the whole system fall over?
Or can should they slow down the request/response speed by putting people in a queue that sits in front of your service?
3. Graceful Degradation
They found techniques such as graceful degradation effective in such scenarios.
They designed fallbacks, such as showing unpersonalized content or removing the non-critical features from the website.
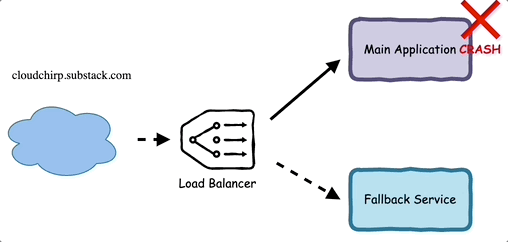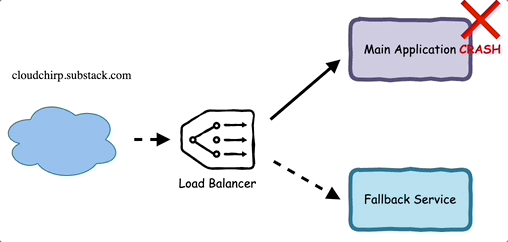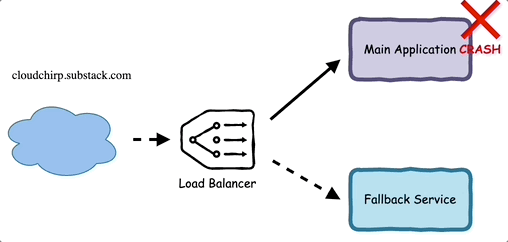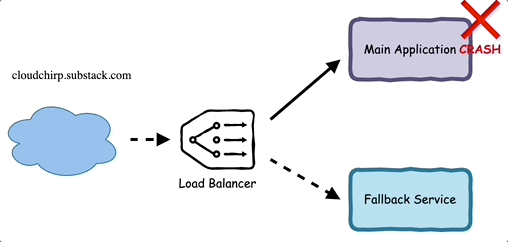
But after all, they still needed to serve the people.
4. Serverless
So they took a step beyond this and went serverless.
Cloud-based elastic compute resources are expected to get rid of these capacity-based limitations.
However, while a technology like serverless allowed them to deal with a 10x or even 100x increase in load, doing so had to be paid for.
So if it wasn’t profitable traffic, they didn’t necessarily want to scale to support it.
5. Traffic Prioritization
As a ticket selling website, you’re more likely to profit from people finishing their purchase rather than the one searching through the feed.
So they decided to prioritize fans in the checkout process over those searching for tickets.
But this still wasn’t solving their issue of serving excess traffic.
6. Fail Fast
But they were smart.
They knew if there’s an excess requests to the system, they better fail fast, rather than allowing all that traffic through and having their system grind to a halt.

Allowing this to happen helped them avoid underlying issues and retry to a different instance of the service, or serve a degraded experience.
So they eventually figured out the incidents were almost inevitable, and they at least wanted to be prepared for them.
7. Red vs. Blue Team
So before the event they decided to ran multiple red team/blue team exercises.
The goal was not having someone thinking about how a system is properly bulletproof.
Rather it was having someone thinking about how a system could break.
Nonetheless, they still knew the worst can happen and they should plan for it.
8. Preparing for Incidents
While some incidents may look familiar — a denial-of-service (DoS) attack, say — some are novel and require a lot of improvisation and quick thinking.
The general idea they had is that they declare an incident, choose an incident commander, then have one or more subject matter experts working on the issue.
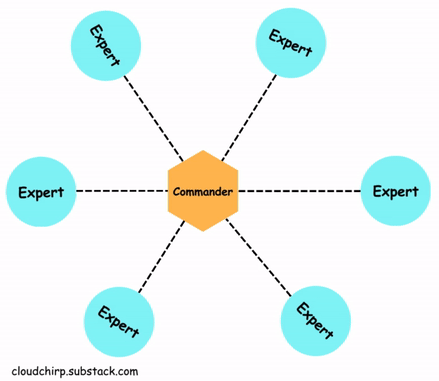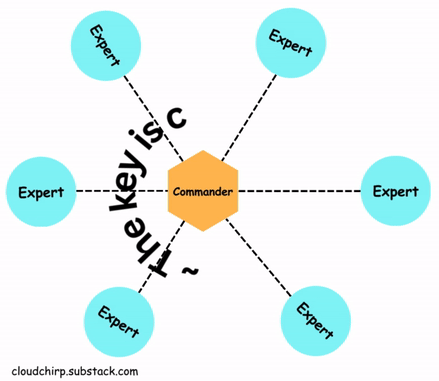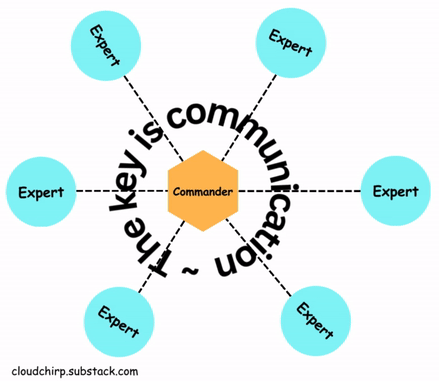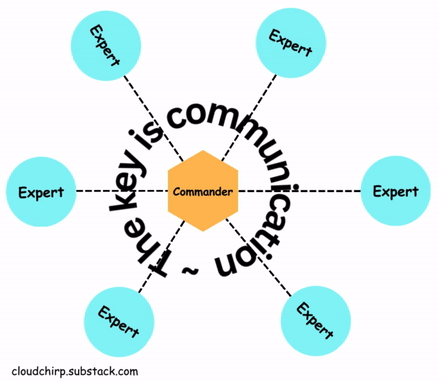
The incident commander isn’t hands-on; they are in a coordination role and are key to making the approach work.
Adding to this, with a major incidents, know that while you’re trying to solve the problem, The New York Times is writing a front-page story on why your website is down.
The harsh reality is:
The probability of failures still exists but they reduced the risk of downtime. And limited the scope of impact.
And everybody lived Happily ever after.
I hope you find these resources as enlightening as I did. Stay tuned for more exciting developments and updates in the world of cloud computing in next week's newsletter.
Until then, keep innovating and soaring in the cloud! ☁️
Warm regards, Teodor